SQL의 제약조건
---------------------------------------------------------------------------------
# 제약조건이 설정 된 경우 #
---------------------------------------------------------------------------------
2) salary칼럼에 check제약조건 추가
drop table c_emp;
create table c_emp(
id number(5)
,name varchar2(25)
,salary number(7,2) constraint c_emp_salary_ck check(salary between 100 and 1000)
,phone varchar2(15)
,dept_id number(7)
);-> salary 칼럼에 숫자의 제약을 걸어주었다.
insert into c_emp(id,name,salary)
values(1,'happy',100);
insert into c_emp(id,name,salary)
values(1,'smile',1000);
insert into c_emp(id,name,salary)
values(1,'yolo',10000); //error

-> insert를 해주었다. yolo의 salary값을 10000을 주었더니 오류발생했다.
3) name칼럼에 unique제약조건 추가
drop table c_emp;
create table c_emp(
id number(5)
,name varchar2(25) constraint c_emp_name_un unique
,salary number(7,2)
,phone varchar2(15)
,dept_id number(7)
);
-> name칼럼에 unique 제약조건을 걸어주었다.
insert into c_emp(name) values('smile');
insert into c_emp(name) values('smile');

-> 같은 name을 가진 두 insert를 넣어보았다. unique에 걸려 두번째 smile에 오류가 생겼다.
4) dept_id칼럼에 foreign key제약조건 추가
drop table c_emp;
create table c_emp(
id number(5)
,name varchar2(25)
,salary number(7,2)
,phone varchar2(15)
,dept_id number(7) constraint c_emp_dept_id_fk foreign key
);
--부서테이블 확인
select * from dept;

-> dept_id칼럼에 foreign key 제약조건을 넣었다. 이때, 전에 만들어주었던 부서테이블 dept에 맞게 dept_id의
number수를 정한다.
insert into c_emp(name,dept_id) values('망고',10);
insert into c_emp(name,dept_id) values('복숭아',40);
insert into c_emp(name,dept_id) values('포도',90);

-> insert를 해주었다. 마지막 포도의 id 90에서 오류가 발생했는데 이 이유는 dept 부서테이블에 90은 존재하지 않으므고 오류가 생겼다.
5) 제약조건 최종결과값
create table c_emp(
id number(5) primary key
,name varchar2(25) not null
,salary number(7,2) check(salary between 0 and 100)
,phone varchar2(15) null
,dept_id number(7) references dept(deptno)
);
--제약조건 목록 확인(데이터사전)
select * from user_constraints where table_name='C_EMP';

SQL 정의서 작성해서 테이블 만들기
SQL문의 테이블을 생성하기 전, 시나리오와 정의서를 작성하면 보기 쉽게 테이블을 만들 수 있다. 또한 후의 수정 문제에서도 쉽게 찾을 수 있어 쿼리문 작성 전 먼저 시나리오파일과 정의서 파일을 만들어 놓는 것을 추천한다.
1. 테이블 시나리오 & 정의서 작성하기
- 먼저 시나리오 작성 후, 정의서를 작성한다. 정의서를 토대로 테이블을 만드는 것이다.


2. 정의서로 테이블 생성하기
1) 테이블 생성
- 제약조건을 자세히 보고 입력한다.
drop table sungjuk;
create table sungjuk(
sno number primary key
,uname varchar(50) not null
,kor number(3) check(kor between 0 and 100)
,eng number(3) check(eng between 0 and 100)
,mat number(3) check(mat between 0 and 100)
,tot number(3) default 0
,aver number(5,2) default 0
,addr varchar(30) check(addr in ('Seoul','Jeju','Suwon','Busan'))
,wdate date default sysdate
);
2) value 값넣기
- default 값 0 준거 확인해보기
insert into sungjuk(sno,uname,kor,eng,mat,addr)
values(1,'손흥민',77,88,99,'Seoul');

-> tot, aver, wdate는 default값이 정해져있다. 정해져있는 default값으로 나온것을 볼 수 있다.
**관계형 DB에서 테이블의 핵심기능
| C | Create | insert문 |
| R | Read | select문 |
| U | Update | update문 |
| D | Delete | delete문 |
SQL Sequence
1) 시퀀스 : 자동으로 일련번호 부여
- 아무것도 없이 create sequence table; 만 한다면 증가값 1, 최대값1로 기본값이 설정된다.
drop sequence sungjuk_seq; --시퀀스 삭제
create sequence sungjuk_seq --시퀀스 이름
increment by 1 --증가값
start with 103 --시작값
maxvalue 10000000 --최대값
nocache --캐쉬사용여부
nocycle; --순환여부
2) 시퀀스 호출 함수
주의 : 시퀀스 생성 후 nextval을 호출해야 시퀀스에 초기값이 설정됨
- nestval : 다음값을 반환함. 다음번호 발금
select sungjuk_seq.nextval from dual;
- currval : 현재값을 반환함. 최근 발급된 번호
select sungjuk_seq.currval from dual;
문제1) 시퀀스 문제
c_emp 테이블에 데이터 입력시 sequence를 이용해서 id를 입력하도록 206에서 시작하여 1씩 증가되고,
최대값은 999로 설정하여 시퀀스를 생성하시오.
시퀀스 이름 : c_emp_seq
create sequence c_emp_seq
increment by 1
start with 206
maxvalue 999;
3) 서브쿼리를 이용한 일련번호 발급
주의 : 시퀀스와 혼합해서 사용하지 않도록 주의
--시퀀스 목록 조회
select * from user_objects
where object_type='sequence';
--레코드 전부삭제
delete from sungjuk;
--국어점수의 최고점 조회
select max(kor) from sungjuk;
--nvl() null값이 나오면 0으로 바꿈
select nvl(max(kor),0) from sungjuk;
--서브쿼리를 이용한 일련번호 부여
select nvl(max(kor),0)+1 from sungjuk;
insert into sungjuk(sno,uname,kor,eng,mat,addr)
values((select nvl(max(kor),0)+1 from sungjuk),'손흥민',99,88,77,'Seoul');
select * from sungjuk;

SQL 동일한 데이터
1) distinct : 칼럼에 중복내용이 있으면 대표값 1개만 출력
형식) distinct 칼럼명
select addr from sungjuk;
select distinct(addr) from sungjuk;
2) group by절 : 칼럼에 동일 내용끼리 그룹화 시킴
형식) group by 칼럼명1, 칼럼명2, ~
select addr from sungjuk group by addr;
select addr,uname from sungjuk group by addr; //error
-> group by에 의한 결과값이 오로지 1개만 존재하는 값만 조회할 수 있다.
집계함수와 많이 사용한다.
SQL 집계함수
select count(*), --레코드갯수
sum(kor), --국어점수 합계
avg(eng), --영어점수 평균
max(mat), --수학점수 최고점
min(tot) --총점 최저점
from sungjuk;

문제) 각 주소별 인원수를 구하시오
select addr,count(*) from sungjuk group by addr;
select addr,count(*) as cnt from sungjuk group by addr;

--주소별 인원수를 구한 후 주소순으로 정렬하시오
select addr, count(*) from sungjuk group by addr order by addr;
--주소별 인원수를 구한 후 인원수순으로 내림차순 정렬하시오
select addr, count(*) from sungjuk group by addr order by count(*) desc;

--주소별 국어점수 평균을 구한 후 국어점수 평균순으로 내림차순 정렬해서 조회하시오
select addr, avg(kor) from sungjuk group by addr order by avg(kor) desc;
--소숫점을 없애줌
select addr, round(avg(kor),0) from sungjuk group by addr order by avg(kor) desc;

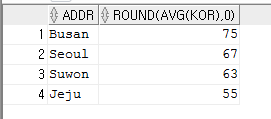
--지역별 국,영,수 최고점을 지역별순으로 정렬해서 조회하시오
select addr,max(kor),max(eng),max(mat) from sungjuk group by addr order by addr;

--1차값이 동일하다면 그 그룹내에서 2차 그룹이 가능하다
--지역별로 그룹핑을 하고 만일 지역이 동일하다면 수학점수별로 그룹핑을 하시오
select addr,mat from sungjuk group by addr,mat;
문제) aver칼럼값을 구한 후 aver칼럼값이 50이상인 레코드 대상으로 지역별 국영수 평균을 반올림해서 소수점 1자리까지 구한 후 조회하시오
--aver 구하기
update sungjuk set aver=(kor+eng+mat)/3;
select addr,round(avg(kor),1) as a_kor,
round(avg(eng),1) as a_eng,
round(avg(mat),1) as a_mat
from sungjuk where aver>=50 group by addr order by addr;
SQL 조건절
|
where 조건절 |
|
| having 조건절 | group by와 함께 사용 |
| on 조건절 | 테이블 조인할 때 사용 |
1. having 조건절
select addr,count(*) from sungjuk group by addr;
select addr,count(*) from sungjuk group by addr having count(*)=3;

문제) 지역별 국어점수 평균을 구한 후 그 평균이 80점 이하 지역만 조회
select addr, round(avg(kor),1) from sungjuk group by addr having avg(kor)<=80;

문제) 지역별 국어점수 평균을 구한 후국어평균 60-79사이인 지역만 조회
select addr,round(avg(kor),1) from sungjuk group by addr having avg(kor) between 60 and 79;

-> 점수를 다양하게 안줘서 데이터가 겹친다 ! ^^,,,,,
'공부 > SQL 활용' 카테고리의 다른 글
| 7월25일 - SQL 활용 5 : JOIN (0) | 2019.07.25 |
|---|---|
| 7월24일 - SQL활용 4 : View & Index (0) | 2019.07.24 |
| 7월22일 - SQL활용 3 : 함수 (0) | 2019.07.22 |
| 7월22일 - SQL 활용연습문제 (0) | 2019.07.22 |
| 7월18일 - SQL활용 1 (0) | 2019.07.18 |



